








SQL Server Filegroup Oluşturma&Kullanımı
Merhabalar,
Veritabanı sistemlerinde yer alan tablolarımızın sayısı ve üzerinde barındırdığımız verilerimiz gün geçtikçe monoton artan bir yapıyla çoğalmaktadır. Bu tablo ve verilerin geçmişi bir hayli eskiye dayanan şirketlerde ise her saniye artan veri miktarıyla birlikte veritabanına , disklere, sunucuya ekstra yükler binmeye başlar. Bu da zamanla performans sorunlarına sebep olmaya başlar.
“Sorgular yavaş geliyor.”
“Top 1000 atıyorum ama yine de uzun sürüyor.”
Bu tarz bir durumda bakılacak birden fazla nokta olmakla birlikte bu yazımızın konusu olan Filegroup üzerinden sorunlarımızın kaynağına inmeye çalışalım.
SQL Server’da veritabanı oluşturulurken bir data file (mdf) ve bir log file (ldf) dosyaları otomatik olarak oluşmaktadır. Fakat bir DBA olarak bu veritabanının zamanla ulaşacağı büyüklüğü ve işlem sayısını da göz önünde bulundurarak bu dosya sayılarını artırmamız gerekebilir. Öngörülemeyen bir büyüme ivmesi kaydeden veri tabanı bazı problemleri de beraberinde getirecektir.
Bir E-ticaret şirketi düşünelim. Yaptığımız alışverişlerin son 3-6 aylık kısmını görüntülememiz çoğu zaman yeterli olmaktadır. Fakat 5-6 yıl önce vermiş olduğumuz siparişi kullanıcıya her seferinde göstermek ve bunu milyonlarca müşterinin her birisi için yapmak sunucuya ekstra yük bindirmektedir. Bu durumu sağlıklı bir DWH kurgulaması ile önleyebileceğimiz gibi filegroup ile de kısmen çözüm üretebiliriz.
Ya da veritabanı üzerinde 100 tablo var ve toplamda 10 TB olduğunu düşünelim. Bu 100 tablo arasından en sık kullanılan ve en büyük tabloları daha hızlı bir diske aktarsak nasıl olur ? Peki ya indexlerimizi başka bir disk üzerinde barındırmak ?
İşte bu noktada bizim PRIMARY olarak belirlenen mdf dosyamıza alternatif olarak, başka bir diskte olabileceği gibi aynı disk üzerinde de yapabileceğimiz ekstra bir data file oluşturup(ndf) bu dosya üzerine de yoğun kullanılan tablolarımızı taşımak oldukça fayda sağlayacaktır.
Bu şekilde bir yapılandırma ile 20 milyon kayıtlı bir tabloda 1 kayıt çekmek yerine bu tabloyu filegroup üzerinde bölerek daha küçük veri grupları arasından verimizi çekebiliriz. Böylece son yılın verileri lazım olduğunda tüm yıllara ait verileri okumak yerine gerçekten ihtiyacımız olan verileri çekeriz. Bununla birlikte I/O kullanımını azaltmış olup hem sunucuya yük bindirmemiş hem de verilerimizi daha az maliyetle daha hızlı çekmiş oluruz.
Bu kadar detayın üzerine bir filegroup oluşturalım ve bu filegroup üzerinde yeni bir index oluşturalım.
Filegroup Tanımlama
Filegroup oluşturmak istediğimiz veritabanına gelip sağ tıklıyoruz ve Properties diyerek açılan menüden Filegroups kısmına geliyoruz.

Görüldüğü üzere bir adet PRIMARY isminde filegroup mevcut.
Add Filegroup dedikten sonra PRIMARY yazan satırın altında bir satır eklenecek ve bu alandan Filegroup için bir isim belirliyoruz.
Daha sonra solda yer alan Files sekmesine geliyoruz ve bir ndf dosyası oluşturuyoruz.

Görüldüğü üzere Secondary Filegroup üzerinde AdventureWorks2017_fg isminde bir file oluşturduk. Bu dosyayı daha hızlı bir disk üzerinde ya da disk alanı daha fazla başka bir disk üzerinde barındırabilirim. Oluşturmuş olduğum bu dosyanın uzantısı ise ndf olarak belirlenmekte ve bundan sonra oluşturacağım dosyaların da uzantısı yine aynı şekilde ndf olacaktır.
Bazı durumlarda da büyük tabloları barındıran filegrouplar için read only seçme ihtiyacı duyabiliriz. Böyle bir durumda Filegroup sekmesinde ilgili filegroup için read only seçeneğini işaretlememiz gerekir. Bu noktada dikkat etmemiz gereken nokta ise database üzerinde bir session açıksa Read only’e izin vermeyip hata basacaktır.
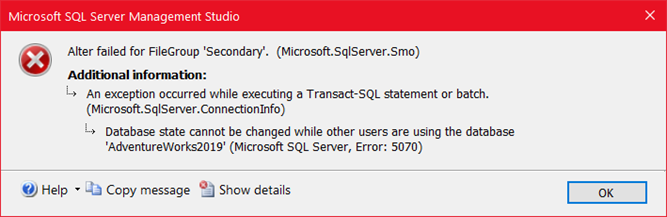
Böyle bir durumda session kill edilebilse de genel olarak tercih edilemeyen durumlarda Read only’i işaretledikten sonra script yazan yere tıklayıp script oluşturabilirsiniz. Bu scripti ,
ALTER DATABASE AdventureWorks2019 SET SINGLE_USER WITH ROLLBACK IMMEDIATE
<Script>
ALTER DATABASE AdventureWorks2019 SET MULTI_USER WITH ROLLBACK IMMEDIATE
şeklinde düzenlediğimizde sorun ortadan kalkacaktır.
Filegroup Üzerinde Index Tanımlama
Şimdi de oluşturmuş olduğumuz bu filegroup üzerinde bir index oluşturalım.
Bunun için AdventureWorks2019 veritabanında Production.Product tablosuna geliyorum ve New Index diyorum.

Açılan menüde Add diyerek ProductNumber kolonu için bir NonClustered index tanımlayacağım.
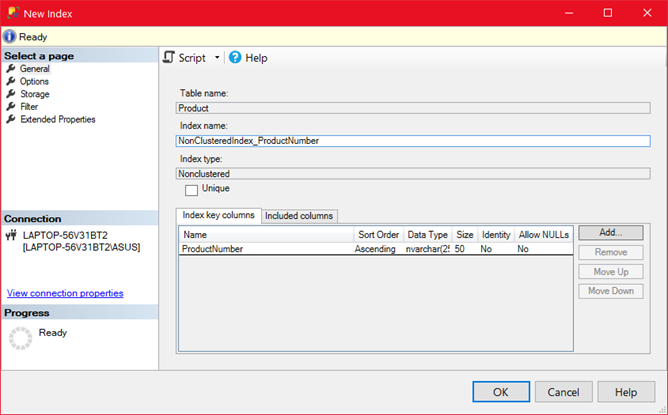
Index ismini de verdikten sonra Storage sekmesine geliyorum. Burada Filegroup kısmından Secondary seçiyorum ve OK ile index oluşturmayı tamamlıyorum.
Filegroup Backup Almak
Son olarak ise AdventureWorks2019 dbsinde oluşturmuş olduğumuz AdventureWorks2017_fg file için backup alalım. Bunun için AdventureWorks2019 dbsine sağ tıklayıp Task—Backup diyoruz. Açılan menüde dbmizin FULL recovery modda olduğunu gördük ve Backup Component kısmından Files and Filesgroup seçiyoruz. Açılan menüde hangi filegroup altındaki file için backup almak istiyorsak onu seçiyoruz ve OK diyip yedeğimizi alıyoruz.

Filegroup oluşturup yoğun kullanılan tabloları farklı dosyalar ve farklı diskler üzerinde barındırmak için bu yazıdan Table Partition yazısını okuyabilirsiniz.
Filegroup kullanım amaçlarını, index oluşturmayı ve backup almayı anlattığım bu yazıda faydalı bilgiler bulmanız umuduyla.
Hoşça kalın.