


SQL Server Veritabanı Filegroups Arasında Veri Taşıma
Projelerimizin gereksinimlerine göre bazı büyük tablolardaki eski verileri ayrı bir dosya grubuna arşivlemeyi ve bu dosya grubunu salt okunur hale getirmeyi planlıyoruz. Ancak SQL Server’da veri dosyalarını doğrudan bir dosya grubundan diğerine taşımak mümkün değildir. Veri dosyalarını dosya grupları arasında taşıyamayacağımızdan bir tablonun verilerini bir dosya grubundan diğerine taşımak için kümelenmiş dizin (Clustered Index) kullanılabilir.
Bu yöntemle birlikte, tabloyu yeni bir dosya grubuna taşımak için önce verilerin küme dizini oluşturulur ve ardından bu dizin yeni dosya grubuna taşınır. Bu işlemleri gerçekleştirmek için gerekli adımları uygulamalıyız.
Bu adımları gerçekleştirmek için kendi local ortamımda bulunan AdventureWorks2019 veritabanının en büyük tablosunu kullanarak verileri yeni bir dosya grubuna taşıyacağım.
Öncelikle herhangi bir veritabanındaki en büyük on tabloyu belirlemek için aşağıdaki sorguyu çalıştırabilirsiniz.
SELECT TOP 10 Schema_name([table].schema_id) + '.'
+ [table].NAME
AS [table name],
Cast(Sum([allocationunit].used_pages * 8) / 1024.00 AS
NUMERIC(36, 2)) AS
[used mb],
Cast(Sum([allocationunit].total_pages * 8) / 1024.00 AS
NUMERIC(36, 2)) AS
[allocated mb]
FROM sys.tables [table]
JOIN sys.indexes [index]
ON [table].object_id = [index].object_id
JOIN sys.partitions [partitions]
ON [index].object_id = [partitions].object_id
AND [index].index_id = [partitions].index_id
JOIN sys.allocation_units [allocationunit]
ON [partitions].partition_id = [allocationunit].container_id
GROUP BY Schema_name([table].schema_id) + '.'
+ [table].NAME
ORDER BY Sum([allocationunit].used_pages) DESC;
Resim-1’de görüldüğü üzere boyutu en büyük olan tablomuz Person.Person tablosudur.
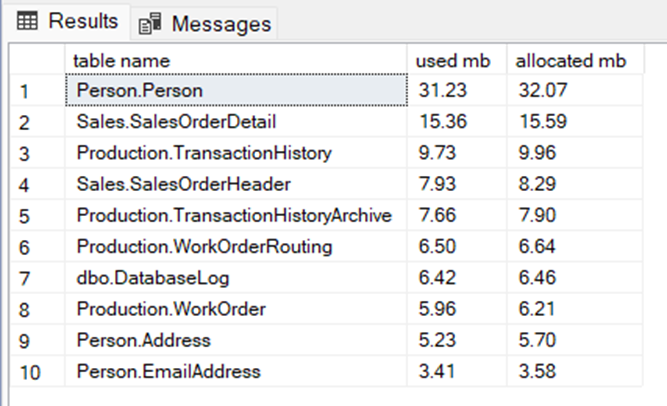
Person.Person tablosu üzerinde işlem yapacağımıza karar vererek FG_AdventureWorks2019_Person adlı ikincil bir dosya grubu(filegroup) oluşturalım . Oluşturmak için aşağıdaki kodu çalıştıralım.
USE [master]
go
ALTER DATABASE [AdventureWorks2019] ADD filegroup [FG_AdventureWorks_Person]
Go
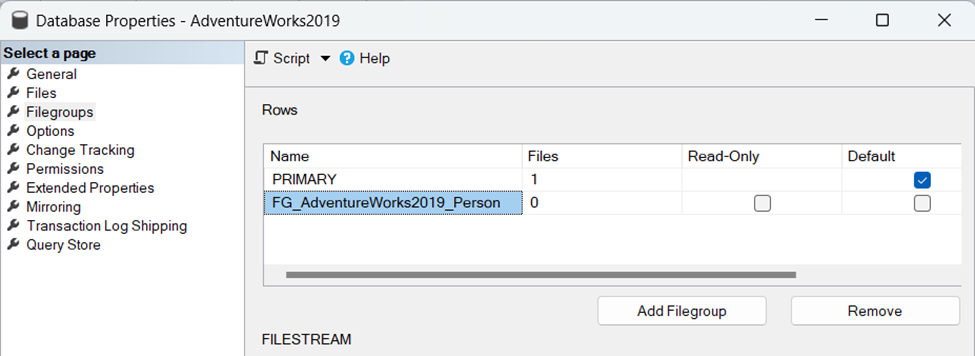
Resim-2’de filegroups’un oluştuğunu görmekteyiz. FG_AdventureWorks2019_Person adlı ikincil bir dosya grubu(filegroup) ile ilişkili veri dosyası C:\AdventureWorks2019 _ Person konumunda oluşturarak, dosya adını AdventureWorks2019_Person.ndf . Başlangıç boyutunu 63.30 MB olacak ve Filegrowth 95.37 MB olacak şekilde veri dosyası oluşturmak için aşağıdaki sorguyu çalıştıralım.
USE [master]
go
ALTER DATABASE [AdventureWorks2019] ADD FILE ( NAME = N'AdventureWorks2019_Person',
filename = N'C:\Program Files\Microsoft SQL Server\MSSQL16.MSSQLSERVER\MSSQL\DATA\AdventureWorks2019_Person.ndf', size =
648192kb, filegrowth =9765888kb) TO filegroup [FG_AdventureWorks2019_Person]
go
Bu şekilde dosya grubuna(filegroup) bağlı olan ikincil veri dosyasını oluşturmuş bulunuyoruz. Aşağıdaki kodu çalıştırdığımızda Resim-3‘de dosya gruplarının ve bu gruplara ait dosyaların listesini görünmektedir.
USE [master]
go
SELECT fg.NAME AS [File Group Name],
sdf.NAME AS [Data File Name],
physical_name AS [Data file location],
size / 128 AS [File Size in MB]
FROM sys.database_files sdf
INNER JOIN sys.filegroups fg
ON sdf.data_space_id = fg.data_space_id

Devamında kümelenmiş indeksi(Clustered Index) yeniden oluşturarak tabloyu isimli ikincil dosya grubuna nasıl taşıyacağımıza bakalım.
Person.Person tablosu, PK_Person_BusinessEntityID adında bir clustered index’e sahiptir. Biz bunu ikincil dosya grubu olan [FG_AdventureWorks2019_Person] filegroup’a taşıyacağız. Taşıma işlemi için aşağıda bulunan kodu çalıştıralım.
USE [AdventureWorks2019]
GO
CREATE CLUSTERED INDEX PK_Person_BusinessEntityID ON [Person].[Person] ([BusinessEntityID]) WITH (DROP_EXISTING = ON)
ON [FG_AdventureWorks2019_Person] ;
Taşıma işlemini kontrol etmek için aşağıda bulunan kodu çalıştıralım.
USE [AdventureWorks2019]
go
SELECT [objects].[name] AS TableName,
[index].[name] AS IndexName,
[filegroup].[name] AS FileGroupName
FROM sys.indexes [index]
INNER JOIN sys.filegroups [filegroup]
ON [index].data_space_id = [filegroup].data_space_id
INNER JOIN sys.all_objects [objects]
ON [index].[object_id] = [objects].[object_id]
WHERE [index].data_space_id = [filegroup].data_space_id
AND [filegroup].NAME <> 'PRIMARY'
AND [objects].NAME = 'Person'
Çalıştırdığımız kodla taşıma işleminin gerçekleştiğini görmekteyiz.

Son adım olarak dosya grubunu salt okunur olarak yapılandıralım.
ALTER DATABASE AdventureWorks2019 MODIFY FILEGROUP FG_AdventureWorks2019_Person READ_ONLY
GOVeritabanımızın altında Person tablosuna sağ tıklayarak Storage alanında filegroups’un değiştiğini görmekteyiz.
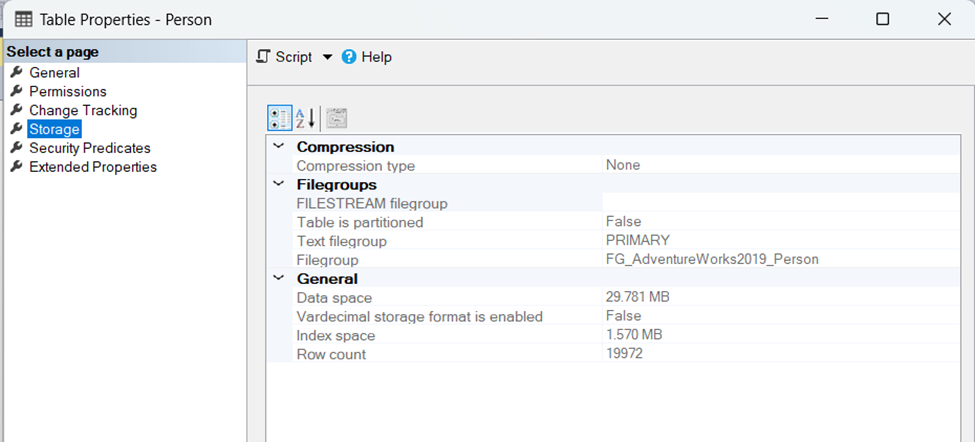
Bu yazımda SQL Server veritabanı dosya grupları arasında veri taşıma işlemini gerçekleştirmiş bulunmaktayız umarım faydalı olmuştur.
Kaynak
https://www.mssqltips.com/sqlservertip/2442/move-data-between-sql-server-database-filegroups
https://www.sqlservercentral.com/forums/topic/how-do-you-move-a-datafile-to-another-filegroup
https://stackoverflow.com/questions/46481448/move-file-group-to-a-different-database
https://www.sqlshack.com/how-to-move-tables-to-another-filegroup-of-a-sql-database/