


PostgreSQL Performans İyileştirme Rehberi: Autovacuum, Indexler ve Paralel Sorgular
Veritabanı sistemlerinin sağlıklı ve yüksek performansla çalışabilmesi için arka planda pek çok süreç yönetilmelidir. PostgreSQL, gelişmiş özellikleri sayesinde büyük veri setlerinde dahi tutarlı ve hızlı sonuçlar üretebilir. Bu yazıda, PostgreSQL’de performans iyileştirme açısından kritik rol oynayan üç konuya odaklanacağız:
- Autovacuum Ayarları
- Index Seçimi
- Paralel Sorgular
1. Autovacuum Ayarları

PostgreSQL, MVCC (Multi-Version Concurrency Control) yapısını kullanır. Bu yapı sayesinde işlemler birbirini blocklamadan aynı tablo üzerinde çalışabilir. Ancak bu durum, dead tuples zamanla şişmesine neden olur. İşte bu noktada Autovacuum devreye girer.
Neden Önemli?
Eğer Autovacuum düzgün ayarlanmazsa;
- Sorgular yavaşlar,
- Disk alanı gereksiz şekilde artar,
- Indeksler şişer ve sorgu planları bozulur.
Temel Autovacuum Ayarları
Autovacuum davranışını PostgreSQL’in postgresql.conf dosyasındaki bazı parametrelerle özelleştirebilirsin:
1. Genel Ayarlar
autovacuum = on
Autovacuum’un çalışıp çalışmayacağını belirler. Varsayılan olarak on‘dur.
autovacuum_naptime = 1min
Her autovacuum döngüsü arasında beklenen süre. Önerilen: 30s – 1min.
autovacuum_max_workers = 3
Aynı anda kaç Autovacuum işlemi çalışabilir? Büyük veritabanlarında 5+ olabilir.
2. Trigger Ayarları
Autovacuum’un bir tabloyu ne zaman işleyeceğine karar vermek için kullanılır.
autovacuum_vacuum_threshold = 50
autovacuum_vacuum_scale_factor = 0.2
Bu iki ayar, aşağıdaki parametre autovacuum’u tetikler:
vacuum_threshold = vacuum_threshold + (scale_factor * tablo_satır_sayısı)
Örneğin 10.000 satırlık bir tablo için:
50 + (0.2 * 10000) = 2050
Bu tabloda 2050’den fazla dead tuples varsa autovacuum devreye girer.
3. Analyze Ayarları
autovacuum_analyze_threshold = 50
autovacuum_analyze_scale_factor = 0.1
Veri dağılımını etkileyen değişikliklerde PostgreSQL’in istatistikleri yeniden oluşturması gerekir. Bu eşik aşıldığında ANALYZE yapılır.
4. Performans Ayarları
autovacuum_vacuum_cost_delay = 20ms
autovacuum_vacuum_cost_limit = -1
Autovacuum’un sistem kaynaklarını ne kadar tüketeceğini kontrol eder:
vacuum_cost_delay: Her belirli adımda duraklama süresi (ms).vacuum_cost_limit: Ne kadar iş yükü üstlenebileceği (varsayılan-1: global ayara göre).
Yoğun çalışan sistemlerde bu değerler iyileştirilerek daha agresif veya daha yumuşak çalışması sağlanabilir.
Tablolara Özel Ayarlar
Her tablo için özel autovacuum ayarları yapabilirsin:
ALTER TABLE public.orders
SET (autovacuum_vacuum_threshold = 100, autovacuum_vacuum_scale_factor = 0.05);
Bu ayar, sadece orders tablosu için geçerli olur. Büyük tablolar için bu tür özelleştirme performans artışı sağlar.
Autovacuum’u İzleme
SELECT relname,
n_dead_tup,
last_autovacuum,
last_analyze
FROM pg_stat_user_tables
WHERE n_dead_tup > 0
ORDER BY n_dead_tup DESC;Autovacuum mekanizmasının yanlış yapılandırılması veya tamamen devre dışı bırakılması, PostgreSQL sistemlerinde ciddi performans sorunlarına yol açabilir. En yaygın hatalardan biri, bu özelliğin tamamen kapatılmasıdır. Bu durum kısa vadede sistem yükünü azaltıyor gibi görünse de, uzun vadede tabloların şişmesine, sorgu performansının düşmesine ve hatta transaction ID wraparound gibi kritik veri kaybı risklerine neden olabilir. Diğer bir yaygın hata, tüm tablolar için tek tip autovacuum eşiği kullanmaktır. Oysa ki bazı tablolar çok sık güncellenirken bazıları nadiren değişir; bu nedenle tablo bazlı ayar yapmak çoğu zaman daha doğrudur. Ayrıca, autovacuum_vacuum_threshold ve autovacuum_vacuum_scale_factor değerlerinin gereğinden yüksek tutulması, özellikle büyük tabloların geç temizlenmesine sebep olur. Bu da zamanla performans kaybını artırır.
2. Index Seçimi
Veri okuma performansında en büyük farkı doğru index kullanımı yaratır. Ancak fazla veya yanlış index kullanımı da tam tersi etki yapabilir.
En Yaygın IndexTürleri
| Tür | Açıklama |
|---|---|
B-TREE | Eşitlik ve sıralı aramalar için |
GIN | Full-text search ve JSONB için |
HASH | Sadece eşitlik aramaları için (sınırlı kullanım) |
BRIN | Büyük tablolarda aralıklı veri aramaları için |
Gereksiz oluşturulan her index, veri yazma işlemlerini yavaşlatır, diskte yer kaplar ve Autovacuum süreçlerini olumsuz etkiler.
EXPLAIN ifadesiyle Sorgu Analizi:
PostgreSQL’in sorguları nasıl işlediğini ve index kullanıp kullanmadığını analiz etmek için EXPLAIN ifadesinden faydalanabiliriz.
Bu komut, veritabanının sorguyu nasıl yürüttüğünü gösteren sorgu yürütme planını sunar; bu sayede veriye nasıl erişildiği ve indekslerin kullanılıp kullanılmadığı anlaşılır.
Aşağıdaki örnekte olduğu gibi EXPLAIN komutunu kullanarak sorgu planını görebiliriz:
EXPLAIN SELECT * FROM books WHERE author = 'Harper Lee';

PostgreSQL’de Index Kullanımının Optimizasyonu
Indexler, sorgu performansını önemli ölçüde artırsa da, en verimli şekilde kullanılmaları için dikkatli bir şekilde yönetilmeleri gerekir:
- Düzenli Bakım: Özellikle sık veri değişiminin yaşandığı ortamlarda, indeks performansını artırmak için periyodik olarak analiz yapılmalı ve yeniden indeksleme (REINDEX) işlemleri uygulanmalıdır.
- Index Seçimi: Kullanılacak index türü ve indexlenecek sütunlar, sorgu desenleri ve iş yükünün özelliklerine göre dikkatle seçilmelidir. Farklı indexleme stratejilerini deneyerek, en etkili olanı kısa sürede belirlemek mümkündür.
- Sorgu Optimizasyonu: PostgreSQL’in sorgu planlayıcısı (query planner) ve çalıştırma analiz araçları (EXPLAIN/ANALYZE) ile verimsiz sorgular tespit edilip, index kullanımına daha uygun hale getirilebilir.
Sonuç
Indexler, PostgreSQL’de sorgu performansını artırmak için oldukça önemli bir araçtır. Farklı indextürlerini tanımak ve doğru şekilde oluşturmak sayesinde, veritabanı daha hızlı veri erişimi sağlayacak şekilde optimize edilebilir. Ancak etkili bir indeks yönetimi, sadece indeks oluşturmakla sınırlı değildir; aynı zamanda düzenli bakım yapılmalı ve sorgu desenlerine göre hangi sütunların indexleneceğini dikkatlice analiz edilmelidir.
3. Paralel Sorgular
PostgreSQL 9.6’dan itibaren paralel sorgular desteklenmektedir. Bu özellik, büyük veri setlerinde sorgu işlemlerini birden fazla CPU çekirdeğine dağıtarak performansı artırır. Bu da özellikle büyük tablo taramalarında (örneğin COUNT(*), SUM(), AVG() gibi toplu işlemlerde) belirgin performans artışı sağlar.
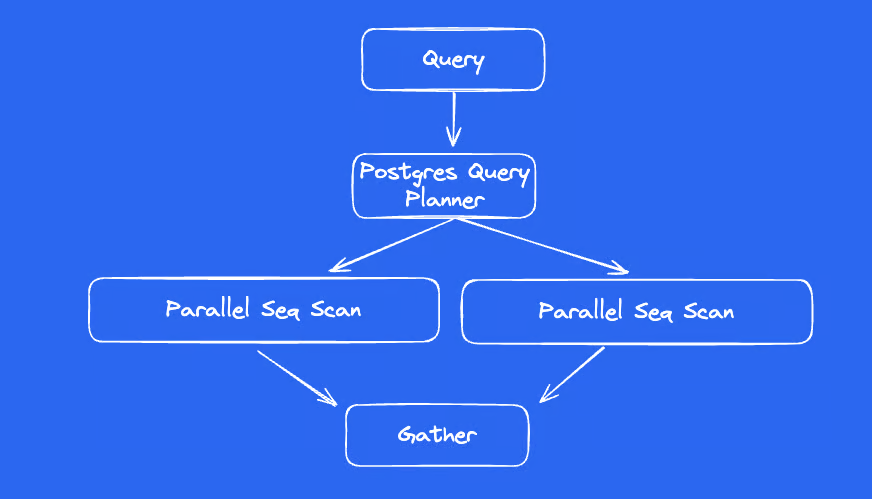
Örnek Sorgu
-- Büyük bir tablo üzerinde paralel sorgu
EXPLAIN (ANALYZE, VERBOSE)
SELECT COUNT(*) FROM big_table WHERE value > 10000;
Çıktıda şunu görmek istersiniz:
Workers Planned: 2
-> Parallel Seq Scan on big_table❗ Not:
Paralel sorgular şunlarla çalışmaz:
- Sıralı işlemler (
ORDER BY) - Yan etkili fonksiyonlar
- LIMIT içeren bazı yapılar
Nasıl Çalışır?
Paralel sorgular aşağıdaki yapı taşlarına dayanır:
- Parallel Seq Scan: Tabloyu birden fazla worker bölüşerek tarar.
- Parallel Index Scan: Uygun index varsa paralel şekilde taranabilir (daha sınırlıdır).
- Gather / Gather Merge: Her worker’dan gelen sonuçları birleştirir.
Yapılandırma Ayarları
Paralel sorguların verimli çalışabilmesi için postgresql.conf dosyasında bazı ayarların optimize edilmesi gerekir:
max_parallel_workers = 8
max_parallel_workers_per_gather = 4
parallel_setup_cost = 1000
parallel_tuple_cost = 0.1
| Ayar | Açıklama |
|---|---|
max_parallel_workers | Sistemde kullanılabilecek toplam paralel worker sayısı |
max_parallel_workers_per_gather | Tek bir sorgu için maksimum worker sayısı |
parallel_setup_cost | Paralel işlem kurulumunun planlayıcıya maliyeti (ne kadar düşükse o kadar paralel eğilimli olur) |
parallel_tuple_cost | Her bir tuple için paralel işlemin ek maliyeti |
Öneri: Daha fazla paralelleşme isteniyorsa parallel_setup_cost düşürülmeli.
Veritabanınızın performansını üst seviyeye çıkarmak için bu üç başlıkta yapacağınız doğru ayarlamalar büyük fark yaratır. Özellikle yüksek trafikli uygulamalarda bu ayarlar, sistemin ölçeklenebilirliği açısından kritik önem taşır.
Kaynakça ;
https://www.geeksforgeeks.org/what-is-an-index-in-postgresql
https://www.postgresql.org/docs/current/runtime-config-autovacuum.html
https://www.enterprisedb.com/blog/postgresql-vacuum-and-analyze-best-practice-tips